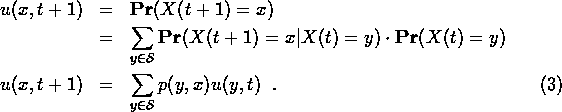(This section assumes familiarity with basic probability theory using mathematicians' terminology. References on this include the probability books by G. C. Rota, W. Feller, Hoel and Stone, and B. V. Gnedenko.)
Many discrete time discrete state space stochastic models are Markov chains.
Such a Markov chain is characterized by its state space, ![]() , and its
transition matrix, P. We use the following notations:
, and its
transition matrix, P. We use the following notations:
and
The first is because the p(x,y) are probabilities, the second because the state x must go somewhere, possibly back to x. It is not true that
![]()
The Markov property is that knowledge of the state at time t is all the information about the present and past relevant to predicting the future. That is:
![]()
no matter what extra history information ( ![]() ,
, ![]() ) we have.
This may be thought of as a lack of long term memory. It may also be
thought of as a completeness property of the model: the state space is rich
enough to characterize the state of the system at time t completely.
) we have.
This may be thought of as a lack of long term memory. It may also be
thought of as a completeness property of the model: the state space is rich
enough to characterize the state of the system at time t completely.
The evolution equation for the probabilities u(x,t) is found using conditional probability:
To express this in matrix form, we suppose that the state space, ![]() ,
is finite, and that the states have been numbered
,
is finite, and that the states have been numbered ![]() ,
, ![]() ,
, ![]() .
The transition matrix, P, is
.
The transition matrix, P, is ![]() and has (i,j) entry
and has (i,j) entry
![]() . We sometimes conflate i with
. We sometimes conflate i with ![]() and
write
and
write ![]() ; until you start programming the computer, there is
no need to order the states. With this convention,
(
; until you start programming the computer, there is
no need to order the states. With this convention,
( ) can be interpreted
as vector-matrix multiplication if we define a row vector
) can be interpreted
as vector-matrix multiplication if we define a row vector
![]() with components
with components ![]() ,
where we have written
,
where we have written ![]() for
for ![]() . As long as ordering is
unimportant, we could also write
. As long as ordering is
unimportant, we could also write ![]() . Now,
() can be rewritten
. Now,
() can be rewritten
Since ![]() is a row vector, the expression
is a row vector, the expression ![]() does
not make sense because the dimensions of the matrices are incompatible
for matrix multiplication. The
convention of using a row vector for the probabilities and therefore putting
the vector in the left of the matrix is common in applied probability.
The relation () can be used repeatedly to yield
does
not make sense because the dimensions of the matrices are incompatible
for matrix multiplication. The
convention of using a row vector for the probabilities and therefore putting
the vector in the left of the matrix is common in applied probability.
The relation () can be used repeatedly to yield
where ![]() means P to the power t, not the transpose of P.
means P to the power t, not the transpose of P.